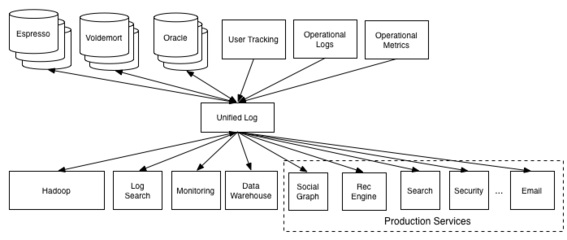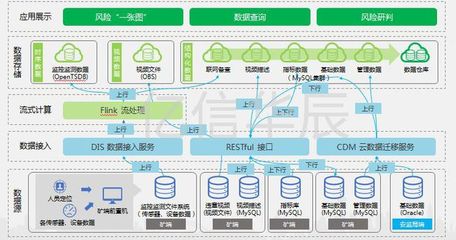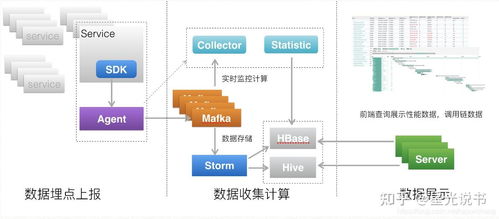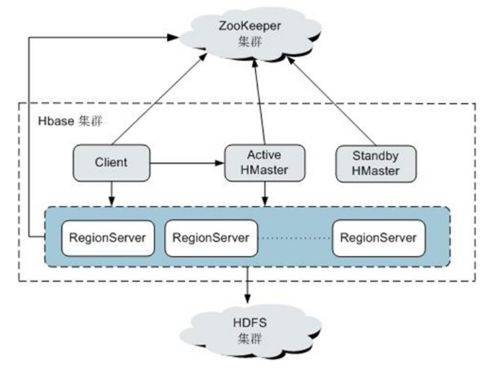
隨著數據量的急劇增長和業務需求的日益復雜,大數據服務組件的規劃與部署成為企業數字化轉型的關鍵環節。其中,數據處理和存儲服務是構建高效、可靠大數據平臺的核心。本文將系統探討大數據服務組件的整體規劃策略,并重點闡述數據處理與存儲服務的部署方案,以助力企業實現數據驅動的業務價值。
一、大數據服務組件整體規劃
大數據服務組件的規劃應以業務需求為導向,結合技術成熟度、可擴展性和成本效益進行綜合考量。核心組件包括數據采集、數據處理、數據存儲、數據分析和數據可視化等模塊。在規劃階段,需明確各組件的功能邊界、交互協議以及容錯機制,確保系統的高可用性和易維護性。同時,采用分層架構設計,如Lambda架構或Kappa架構,能夠有效平衡實時與批量處理的需求。
二、數據處理服務規劃與部署
數據處理服務負責對原始數據進行清洗、轉換、聚合和計算,以生成可供分析的高質量數據。其規劃需關注以下方面:
- 處理引擎選擇:根據業務場景,選用合適的處理框架,如Apache Spark用于復雜批量計算,Apache Flink用于低延遲流處理,或Apache Storm用于高吞吐實時處理。
- 流水線設計:構建端到端的數據處理流水線,包括數據接入、預處理、特征工程和模型訓練等環節,并采用自動化調度工具(如Apache Airflow)管理任務依賴。
- 資源管理:通過YARN、Kubernetes等資源調度器,動態分配計算資源,提升集群利用率。部署時,需配置監控告警系統,實時追蹤作業性能與異常。
三、數據存儲服務規劃與部署
數據存儲服務需滿足多模態數據的持久化需求,并提供高效的讀寫能力。規劃要點包括:
- 存儲架構設計:采用分層存儲策略,結合熱、溫、冷數據的特點,選擇不同類型的存儲系統。例如,使用HDFS或云對象存儲(如AWS S3)作為數據湖基礎,NoSQL數據庫(如HBase、Cassandra)支持高并發訪問,而數據倉庫(如ClickHouse、Snowflake)優化分析查詢。
- 數據治理:實施元數據管理、數據血緣追蹤和數據生命周期策略,確保數據的一致性、安全性與合規性。部署時,需配置備份與容災機制,如跨地域復制和快照技術。
- 性能優化:通過數據分區、索引構建和緩存技術提升查詢效率,同時監控存儲容量與I/O性能,及時進行橫向擴展。
四、集成與運維考量
數據處理與存儲服務的部署需注重組件間的集成與整體運維。利用容器化技術(如Docker)和編排工具(如Kubernetes)可實現快速部署與彈性伸縮。建立統一的日志收集、性能監控和故障診斷體系,結合CI/CD流水線,保障服務的持續交付與穩定運行。
大數據服務組件的規劃與部署是一個系統性工程,數據處理和存儲服務作為基石,其設計需兼顧靈活性、可靠性與成本控制。通過科學的架構選型和細致的運維管理,企業能夠構建出支撐業務創新的大數據平臺,釋放數據潛能,驅動智能決策。